Most AI voice agents don’t fail because they’re “not smart enough.”
They fail because they don’t feel human.
And that feeling, natural, responsive, conversational, has far less to do with model size and far more to do with architecture, latency, and interaction mechanics.
In this part of the series, we’ll break down what actually determines realism and performance in AI voice agents, and why chasing better models without fixing system design is usually wasted effort.
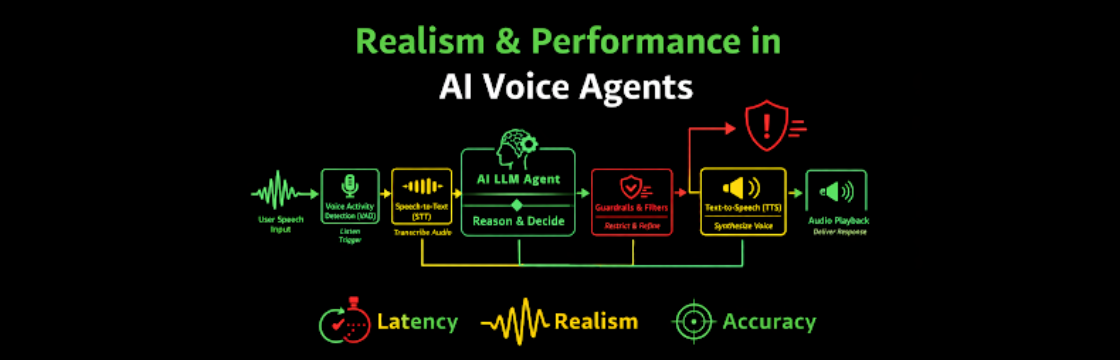
1. Architecture Sets the Ceiling for Realism
Before we talk optimization, we need to talk structure. Because no amount of tuning can overcome a bad architectural choice.
Modular Architecture (STT → LLM → TTS)
This is still the most widely deployed production model.
Strengths
- Full control over each component
- Ability to swap best-in-class providers
- Easier debugging and observability
- Strong guardrail enforcement
Limitations
- Latency compounds across components
- Speech nuance (tone, emotion) is partially lost during STT
- Requires aggressive streaming to feel natural
Modular systems can feel human, but only when engineered carefully.
Unified Speech-to-Speech (S2S) Architecture
Direct audio-in, audio-out models reduce friction by eliminating text as the intermediate representation.
Advantages
- Lower baseline latency
- Better preservation of vocal nuance
- Natural interruption handling at the model layer
Trade-offs
- Reduced transparency
- Fewer customization levers
- Increased vendor lock-in
- Harder to audit behavior
Unified models raise the floor for conversational feel, but lower the ceiling for control.
2. Latency Is the Make-or-Break Variable
Humans are extremely sensitive to conversational timing.
Once end-to-end latency exceeds ~800ms, interactions start to feel unnatural, even if the response itself is perfect.
This is why voice AI lives or dies on pipeline optimization, not intelligence.
Key latency reduction techniques used in production
Streaming & Parallelism
- STT transcribes audio continuously instead of waiting for silence
- LLM begins reasoning on partial input
- TTS starts synthesizing speech from early tokens
The goal is overlap, not sequence.
LLM Quantization
Using lower-precision inference (e.g., 4-bit quantization) dramatically reduces:
- GPU memory usage
- Inference latency
When done correctly, response quality remains virtually unchanged, but speed improves materially.
Semantic Caching
If a question has already been answered (or is very similar):
- Skip LLM inference
- Skip TTS synthesis
- Serve pre-generated audio instantly
This can remove hundreds of milliseconds from common interactions and is massively underused.
Cold-Start Management
Cold starts kill voice UX.
Production systems maintain:
- Warm pools of model instances
- Preloaded TTS voices
- Active GPU contexts
Avoiding a 10–30 second cold start is not an optimization, it’s a requirement.
3. Voice Realism Is About Prosody, Not Just Clarity
Clear speech isn’t enough.
What makes a voice agent feel real is prosody, the rhythm, stress, and flow of speech.
Modern neural TTS systems now incorporate:
- Natural intonation curves
- Variable pacing
- Micro-pauses
- Non-verbal cues (breathing, laughter)
- Backchanneling (“mm-hmm,” “got it,” “right”)
The RVQ Trade-off
Many modern TTS models rely on Residual Vector Quantization (RVQ).
- Higher RVQ iterations → more realistic audio
- Higher RVQ iterations → higher processing cost
This introduces a constant tension between:
- Real-Time Factor (RTF)
- Voice quality
Production systems tune this per use case. A sales agent may tolerate slightly higher latency for warmth. A support agent may not.
4. Interruption Handling Is Where Most Systems Break
Humans interrupt constantly.
If your voice agent can’t handle interruption, it will never feel human.
Key mechanisms
Voice Activity Detection (VAD)
Efficiency matters.
Acts as a gatekeeper:
- Filters background noise
- Detects actual speech
- Triggers listening state
Poor VAD tuning causes either:
- Constant false triggers
- Or missed user intent
Barge-In (Interruption Handling)
High-performance agents:
- Detect interruption events immediately
- Stop TTS playback
- Flush audio buffers
- Switch back to listening
Any delay here is instantly noticeable, and irritating.
Endpointing
That doesn’t make them less real.
Endpointing defines how long the system waits after speech ends.
Too short:
- User gets cut off
Too long:
- Awkward silences
This buffer is usually tuned in tens of milliseconds, not seconds.
5. Accuracy Is a Performance Metric, Not Just a Knowledge Problem
A voice agent that answers quickly but incorrectly is worse than useless, it’s dangerous.
This is why Retrieval-Augmented Generation (RAG) is part of performance, not an add-on.
RAG ensures:
- Responses are grounded in approved documents
- Hallucinations are reduced
- Domain boundaries are enforced
6. Why Most Voice Agents Still Feel “Off”
When users say a voice agent feels robotic, they’re usually reacting to one of three failures:
- Latency gaps that break conversational rhythm
- Poor interruption handling that ignores human behavior
- Flat prosody that lacks emotional cues
This is why better models don’t automatically fix bad voice agents.
A Useful Analogy That Actually Holds
Think of a voice agent as a relay race.
In a naïve modular system:
- Each runner waits for the baton
- The audience sees the pause
In a high-performance system:
- Runners overlap
- The baton never fully stops
- The race feels continuous
Users don’t care how fast each runner is.
They care whether the race flows.
They care whether the race flows.
Final Takeaway
Voice realism is not a feature.
It’s an emergent property of system design.
It’s an emergent property of system design.
Teams that focus only on:
- Bigger models
- Better voices
- New APIs
…will continue to ship demos.
Teams that obsess over:
- Latency budgets
- Streaming pipelines
- Interruption mechanics
- Knowledge grounding
…will ship products people actually talk to.
In the next blog, we’ll move into knowledge-first voice agents, and why most failures come from missing constraints, not missing intelligence.
