Voice AI has officially crossed the line from “interesting demo” to core business infrastructure.
Not because voice is new.
Not because speech recognition suddenly exists.
But because latency, reasoning, and orchestration have finally converged to a point where voice agents can hold real conversations without falling apart.
Not because speech recognition suddenly exists.
But because latency, reasoning, and orchestration have finally converged to a point where voice agents can hold real conversations without falling apart.
This blog is the first in a deep technical series on Voice and Chatbot systems. The goal is simple: separate what sounds impressive from what actually works in production.
No hype. No vendor worship. Just systems thinking.
1. Why Voice AI Adoption Is Accelerating Now
The strongest driver behind voice AI adoption isn’t novelty, it’s failure tolerance.
Businesses lose revenue when:
- Calls go unanswered
- Customers wait too long
- Humans burn out on repetitive conversations
Multiple industry studies now consistently show that over 60% of callers will not retry a missed first call. Voice agents solve this in the bluntest way possible: they answer every time.
By 2025, voice agents are no longer evaluated on whether they work, but on:
- How fast they respond
- Whether interruptions feel natural
- Whether the voice sounds human enough to sustain trust
Anything less fails quietly and expensively.
2. The “Listen → Think → Speak” Loop (Still the Core Model)
Every voice agent, regardless of platform, still implements the same conceptual loop:
- Listen – Detect and capture speech
- Think – Interpret intent, reason, retrieve data, decide
- Speak – Generate natural audio output
What has changed is how tightly this loop is coupled.
The tighter the loop, the lower the latency.
The looser the loop, the more control you retain.
The looser the loop, the more control you retain.
That trade-off defines modern voice AI architecture.
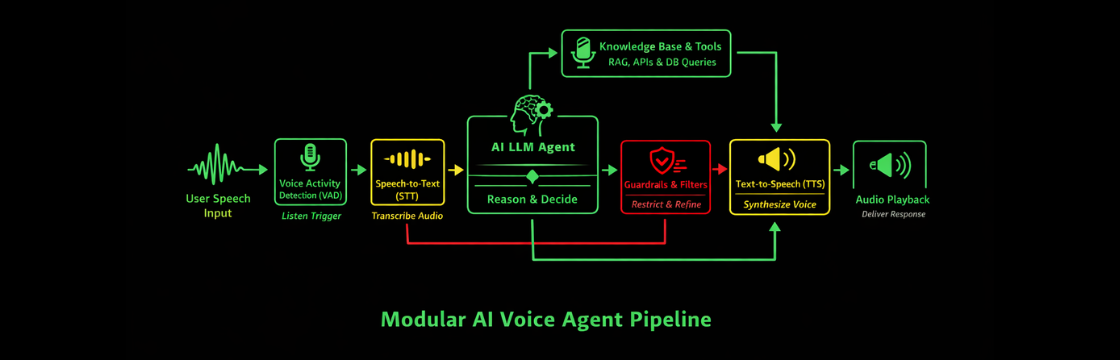
3. Modular (“Sandwich”) Architecture: Still the Most Controllable
STT → LLM → TTS
This architecture remains the dominant production choice for teams that care about reliability, debuggability, and long-term flexibility.
Pipeline components:
- Voice Activity Detection (VAD)
- Speech-to-Text (STT)
- Text-based LLM reasoning
- Tool / knowledge execution
- Text-to-Speech (TTS)
Audio streaming
Why teams still choose it
Pros
- Swap best-in-class providers at each layer
- Immediate access to newest text LLMs
- Easier debugging and observability
- Clear guardrails and deterministic behavior
Cons
- Higher latency if poorly orchestrated
- Requires streaming optimizations to feel natural
- Emotion and tone are partially lost during STT
Despite newer alternatives, serious deployments still default here, especially when compliance, data control, or advanced logic is required.
4. Unified Speech-to-Speech Models: Lower Latency, Higher Lock-In
Unified models collapse the entire loop into a single multimodal system.
This approach became viable with platforms like OpenAI Realtime API, which process audio input and generate audio output directly.
Why they feel impressive
- Sub-500ms conversational latency
- Natural barge-in handling at the model level
- Fewer moving parts
Why teams hesitate
- Reduced transparency
- Limited prompt and tool control
- Vendor lock-in risks
- Harder to audit or constrain behavior
Unified models are excellent for high-touch conversational UX, but they are not yet ideal for deeply regulated or logic-heavy workflows.
5. Latency Is the Real UX Metric (Not Voice Quality)
Human conversation tolerates ~700ms end-to-end latency. Beyond that, interactions feel awkward, even if the voice is perfect.
Latency comes from:
- STT buffering
- LLM reasoning delays
- TTS synthesis time
- Audio transport
Production systems reduce latency by:
- Streaming partial STT
- Streaming TTS audio chunks
- Interrupt-aware buffers
- Pre-emptive response planning
Platforms like Retell AI have gained traction specifically because they handle interruptions (barge-in) gracefully , a feature that users subconsciously expect.
6. No-Code vs Code: This Is a Strategy Decision
No-Code Platforms
Fast deployment. Minimal engineering.
Useful when:
- Prototyping
- Testing market fit
- Handling standard inbound workflows
Limitations:
- Latency tuning is constrained
- Complex logic becomes brittle
- Costs scale poorly at volume
Code-First Systems
Slower to build. Much harder to replace.
Used when:
- You need deep system integration
- You care about cost control
- Voice is business-critical
Frameworks like LangChain and LiveKit exist precisely because voice AI is no longer a toy problem.
7. Voice Quality Still Matters, But Less Than You Think
Human-sounding voices improve trust, but they don’t save broken conversations.
That said, providers like ElevenLabs remain popular because expressive prosody reduces fatigue during longer calls.
In practice:
- Use premium TTS where brand trust matters
- Optimize logic and latency first
- Avoid robotic voices for outbound or sales use cases
8. Cost Reality: Infrastructure Is Cheap, Inference Is Not
One of the biggest misconceptions: cloud hosting is the expensive part.
It isn’t.
Inference dominates cost.
Comparative analysis consistently shows:
- VPS-based deployments are ~3× cheaper than hyperscalers like Amazon Web Services or Google Cloud
- AI model choice impacts cost far more than infrastructure
- Google’s Gemini Live remains significantly cheaper at scale than real-time OpenAI audio models
Optimizing where and how inference runs is now a first-order architectural decision.
9. Voice Agents Fail Without Guardrails
Unbounded agents drift.
They:
- Answer off-topic questions
- Reveal information they shouldn’t
- Hallucinate confidently
Production agents require:
- Strict prompt boundaries
- Tool-only permissions
- Domain-limited knowledge bases
- Explicit refusal behavior
Voice doesn’t remove the need for guardrails; it amplifies the consequences of skipping them.
10. Implementation Reality: Start Narrow or Don’t Start
The fastest failures come from trying to build “general” voice agents.
Successful teams:
- Pick one industry
- Solve one problem
- Instrument everything
- Iterate weekly
Voice agents improve through transcripts, not theory.
What This Series Will Cover Next
This article establishes the technical foundation.
Upcoming parts will go deeper into:
- Knowledge-grounded voice agents (RAG vs live tools)
- Guardrail design patterns
- Voice vs chat trade-offs
- Real deployment architectures
- When unified models win, and when they don’t
Voice AI is no longer experimental.
But building it correctly still is.
